Datenbasis für Ihre KI
Bevor KI in der Produktion etwas bringt, braucht es eine saubere OT-Datenschicht. Genau die bauen wir — damit Ihre Datenleute oder externe ML-Spezialisten überhaupt anfangen können zu arbeiten.
- Konsistente Zeitstempel und Einheiten über alle Maschinen — die Bedingung für jede ernsthafte Auswertung
- Historische Speicherung in Standardformaten (SQL, Parquet) — Ihre Datenleute können sofort arbeiten
- Wir machen die Daten — Sie wählen, ob KI selbst oder mit Spezialisten gemacht wird
SQL · Parquet · Time-Series Quellcode-Übergabe Direkt anrufen
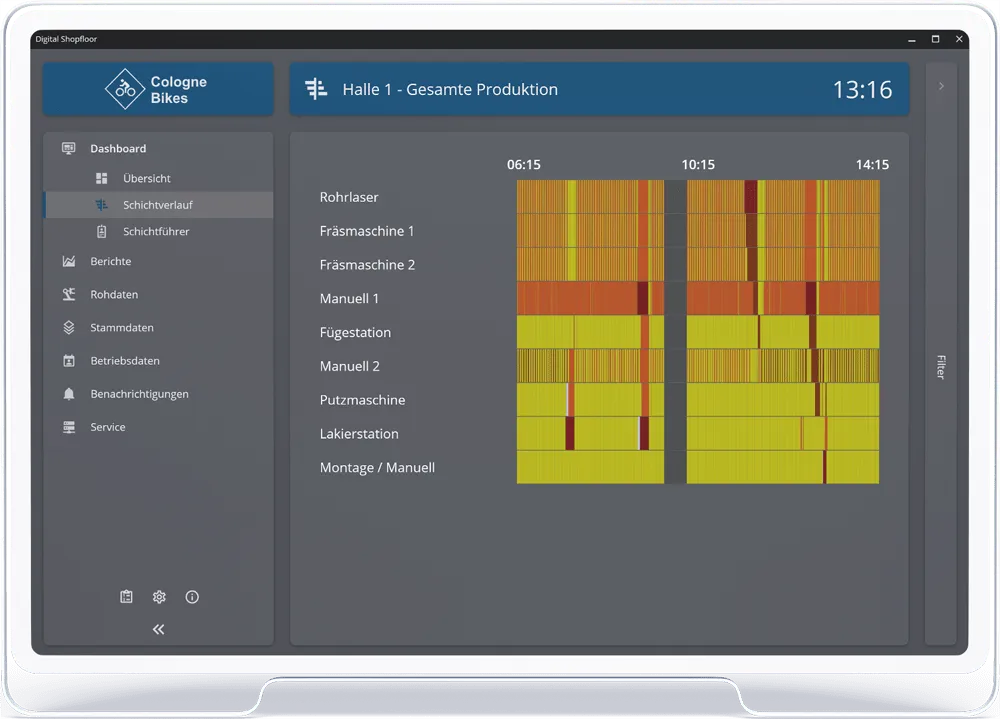
Heatmap aller Maschinen über Zeit — historische Datenbasis, auf der ML-Modelle aufsetzen können
Warum brauchen KI-Projekte in der Produktion eine eigene Datenbasis?
KI- und Analytics-Werkzeuge erwarten saubere, konsistente Datentabellen. Maschinendaten sind aber roh, heterogen und voller Eigenheiten — verschiedene Zeitstempel, unterschiedliche Einheiten, lückenhafte Aufzeichnungen, undokumentierte Sonderfälle. Bevor KI etwas bringt, muss diese OT-Welt in eine Form gebracht werden, mit der Datenwissenschaftler arbeiten können. Auf Produkt-Ebene heißt das etwa, mit der DataSuite Maschinendaten in einer SQL-Datenbank speichern zu können. Genau das ist die Schicht, die wir liefern — im Kern ein Spezialfall der allgemeinen IT/OT-Integration, mit Analytics-Anforderungen als Endabnehmer. Läuft in Ihrer Produktion bereits ein Digital-Shopfloor-System, ist diese Datenschicht schon vorhanden — KI-Projekte setzen dann direkt darauf auf.
Erfassung
SPS, OPC UA, Sensorik, ERP-Daten — alles in einheitliche Zeitreihen
Normalisierung
Konsistente Einheiten, Bezeichnungen, Zeitstempel — eine gemeinsame Sprache
Auslieferung
SQL, Parquet, BI-Tool-Anbindung — Standards, mit denen Ihr Team frei arbeiten kann
Drei Gründe, weshalb KI-Pilotprojekte in der Produktion scheitern
Es liegt selten am Modell. Es liegt fast immer an der Datenbasis darunter.
Inkonsistenz
Zeitstempel passen nicht zusammen
Eine Maschine läuft in UTC, die nächste in Lokalzeit, die dritte in einer eigenen Bordzeit. Modelle, die zeitlich korrelieren sollen, scheitern still — die Ergebnisse sind plausibel, aber falsch.
Datensilo
KI-Team kommt nicht an die Daten
OT ist das eine Reich, IT das andere — und KI-Spezialisten sind in einem dritten unterwegs. Niemand möchte sich mit S7-Datenbausteinen, OPC-Browsing oder Protokoll-Mapping rumschlagen.
Doku-Lücke
Niemand weiß, was die Spalte „Wert_3" bedeutet
Maschinendaten kommen oft ohne Datenmodell. Ohne dokumentierte Bedeutung sind selbst saubere Zahlen wertlos — und Modelle lernen Korrelationen, die keiner überprüfen kann.
Drei Schritte zur belastbaren OT-Datenbasis
Schritt für Schritt — damit Ihre Datenleute am Ende nicht das Mapping-Chaos erben.
1. Quellen erschließen
Maschinen anbinden, Sensoren auslesen, ERP-Daten einbinden. DataSuite als zentraler Sammler — herstellerneutral und dokumentiert.
2. Normalisieren und annotieren
Konsistente Einheiten, einheitliche Zeitstempel, dokumentierte Bedeutung jeder Spalte. Ein Datenmodell, an dem Ihre Datenscientists ohne Rückfragen arbeiten können.
3. Schnittstellen für ML/BI
SQL-Datenbanken, Parquet-Exporte, BI-Tool-Anbindung. Ihr Team wählt das Werkzeug — wir liefern die Daten in der Form, die das Werkzeug erwartet.
Bewährt in datengetriebenen Industrien
Bosch, EEW, Kunz, RWE und viele weitere — Industriebetriebe, die mit unseren Datenflüssen heute KI-Initiativen, Predictive Maintenance und tiefe Auswertungen durchziehen.







Konsistente Zeitstempel
Über alle Quellen — ohne diesen Punkt scheitern Modelle still
Dokumentiertes Datenmodell
Jede Spalte hat eine klare Bedeutung — keine Black-Box-Daten
SQL · Parquet · Time-Series
Formate, mit denen Ihr ML-Team direkt arbeiten kann
![Vanessa und Markus Bläser — das Team von [MB] Software und Systeme aus Wissen im Westerwald](/_astro/Mitarbeiter_Vanessa_und_Markus.BG8p7Qtv_ZA3YYP.webp)
[MB] · Wissen (Sieg)
Datentechnik aus der Produktionsperspektive
Was uns für die Datenbasis-Schicht zur richtigen Wahl macht
- 01
Die unangenehme Wahrheit zuerst
Die meisten KI-Pilotprojekte in der Industrie scheitern nicht am Modell, sondern an der Datenbasis. Wir bauen genau diese Basis, damit Ihr KI-Projekt überhaupt eine Chance hat.
- 02
Wir bauen nicht die KI, wir bauen die Schicht darunter
Klare Aufgabenteilung: Sie behalten die Hoheit über Ihre Modelle und Auswertungen. Wir liefern saubere Daten und dokumentierte Schnittstellen.
- 03
OT verstanden — keine Übersetzungsschwäche
Die meisten KI-Teams kennen Tabellen, kein Maschinendaten-Chaos. Wir kennen beides und bringen die OT-Welt in Formate, mit denen Datenwissenschaftler tatsächlich arbeiten können.
Wir arbeiten gerne direkt mit Ihren KI Experten zusammen.
Fragen, die vor einem KI-Projekt typisch aufkommen
- Bauen Sie selbst KI-Modelle?
- Bewusst nein. Wir machen die Schicht darunter — saubere Datenerfassung, Normalisierung, historische Speicherung, dokumentierte Schnittstellen. Ihre internen Datenscientists oder externe ML-Spezialisten setzen darauf auf, ohne sich mit OT-Eigenheiten herumärgern zu müssen.
- Welche Datenformate liefern Sie für ML/Analytics?
- Standardmäßig SQL-Datenbanken (PostgreSQL, SQL Server, TimescaleDB) und CSV/Parquet-Exporte. Auf Wunsch auch direkte Anbindung an Data Lakes, BI-Tools (Power BI, Grafana) oder ML-Plattformen.
- Wie viel Historie wird gespeichert?
- Standardmäßig zwei Jahre Roh-Daten und unbegrenzt aggregierte Werte. Bei intensiverem ML-Bedarf längere Roh-Historie — Speicherbedarf prüfen wir vorab anhand Ihrer Anlagenanzahl.
- Was unterscheidet eine gute OT-Datenbasis von einer schlechten?
- Drei Dinge: konsistente Zeitstempel über alle Quellen, einheitliche Einheiten und Bezeichnungen, dokumentierte Datenherkunft. Klingt banal — ist aber genau das, woran viele KI-Pilotprojekte in der Industrie scheitern.
- Können wir später eigene Modelle aufsetzen?
- Ja, das ist sogar der Sinn. Wir bauen die Datenschicht so, dass Ihre Datenleute frei darauf arbeiten können — mit jedem Tool ihrer Wahl. Wir geben den Quellcode und die Datenmodell-Doku heraus.
Lassen Sie uns über Ihren Datenfundus sprechen
30 Minuten, kostenlos und unverbindlich. Wir hören zu, schauen auf Ihren aktuellen Datenstand und sagen ehrlich, was Sinn ergibt — bevor Sie Geld in Modelle stecken, die noch keine saubere Basis haben.
Kontaktformular nicht verfügbar
Bitte akzeptieren Sie Marketing-Cookies, um das Kontaktformular zu nutzen, oder kontaktieren Sie uns direkt:
![Markus Bläser — Geschäftsführer [MB] Software und Systeme](/_astro/Markus_Rund.CAviwwJV_IH7CN.webp)
IHR ANSPRECHPARTNER
Markus Bläser
Geschäftsführer · OT-Datenebene für anspruchsvolle Auswertungen